Last Update: 3-13-21 | Official Raspberry Pi Package now available – see bellow
Last Update: 11-9-20 | Updated ventz-media-pi for new Chromium version (v.84+) and new WideVine setup: v.4.10.1679.0+ NOTE: You MUST re-download and re-run it from this date to fix – lots of changes!
Last Update: 11-2-20 | Updated libwidevinecdm.so_.zip to v.4.10.1679.0 within ventz-media-pi
Last Update: 7-22-20 | Updated .desktop with Chrome User Agent string for CrOS Chrome/77.0.3865.120
Last Update: 7-20-20 | ~redacted~ company reached out about creating an official package, also there are conversations happening with ~redacted~ company about official support of the Pi
Last Update: 5-6-20 | Specify that “Raspbian with desktop” is assumed and tested
Last Update: 4-7-20 | Fixed screen tearing
Great News – This can finally be announced:) – There is now an official Raspberry Package with this work!!
Setup everything here with:
|
1 2 3 4 5 |
sudo apt update sudo apt full-upgrade sudo apt install libwidevinecdm0 |
Everything from here down is the “pre-official-raspberry-package” info:
If you just want to take a Raspberry Pi 4 (as of today!) and turn it into a fully functional “Media” center by just pasting one line, here it is:
SSH to your Pi (don’t run from the Pi console if you want pretty graphics :)) and run:
|
1 2 3 4 |
curl -fsSL https://pi.vpetkov.net -o ventz-media-pi sh ventz-media-pi |
This will produce the following (click to see larger image):
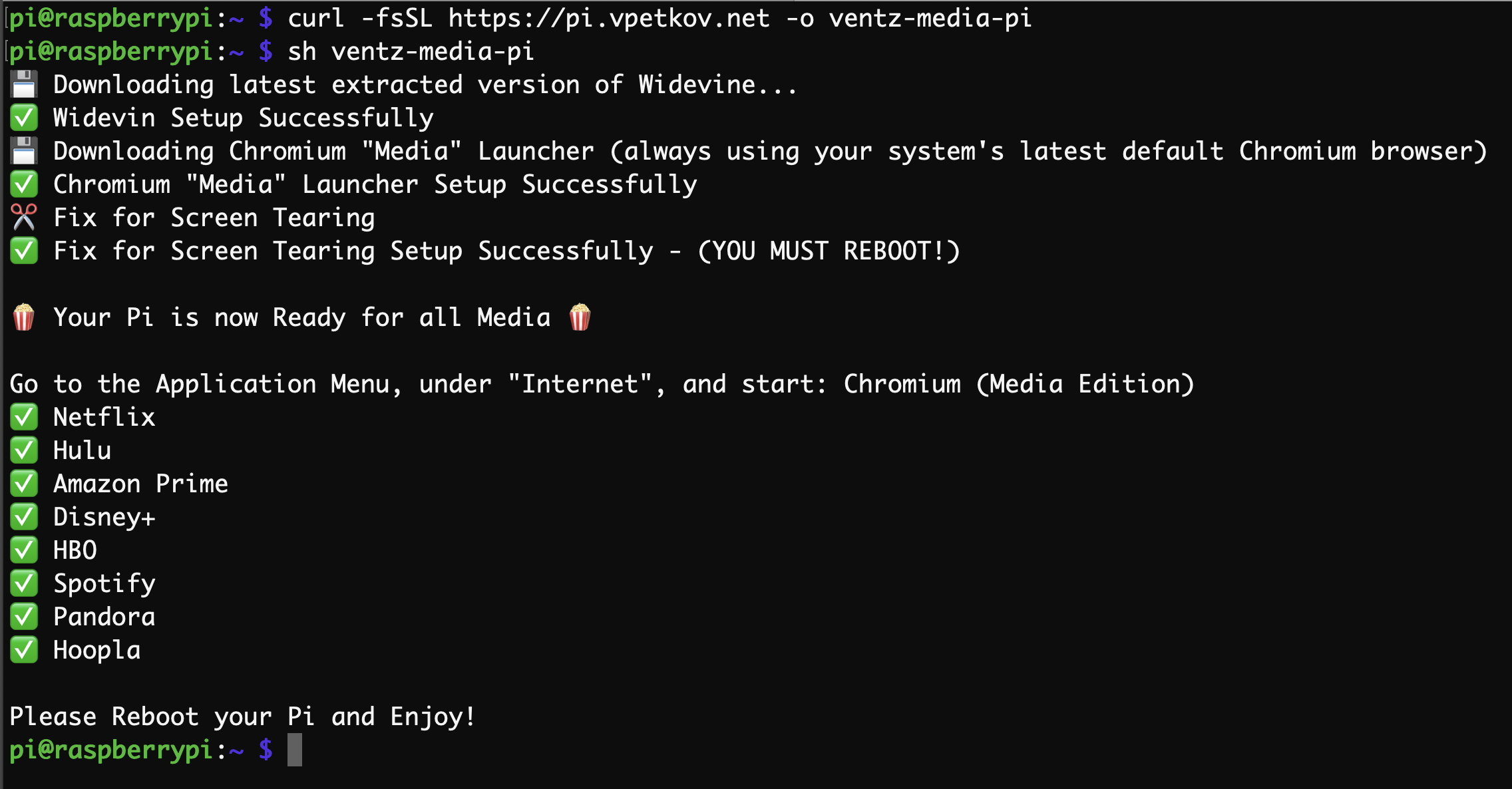
Reboot, and then from the Application Menu (top left) -> go to “Internet” -> open “Chromium (Media Edition)”
You are now ready to use your Raspberry Pi on Netflix, Hulu, Amazon Prime, Disney Plus, HBO, Spotify, Pandora, and many others.
If you need to change any browser Settings, do so via the “Chromium” browser and not the “Chromium (Media Edition) – both are the same browser, so the settings are the same. The “Media Edition” (just a custom launcher with the user-agent) cannot load the settings since Chromium thinks you are launching it on “Chrome OS”, and when it checks for the Chrome OS language settings it crashes since they don’t exist.
At last, all this assumes the latest version of Raspbian with desktop (not Debian/Ubuntu! –
https://downloads.raspberrypi.org/raspbian_latest), and you can re-run the curl and sh as many times as you want without any harm.
If you are curious about some of the background and details on why you can’t easily run Netflix (and others) on your Pi and how to solve it, you are welcome to go look at my “development” blog post article: http://blog.vpetkov.net/2019/07/12/netflix-and-spotify-on-a-raspberry-pi-4-with-latest-default-chromium/
Enjoy!